Eventually I've finished Monte-Carlo difficulty estimate for Project Helena.
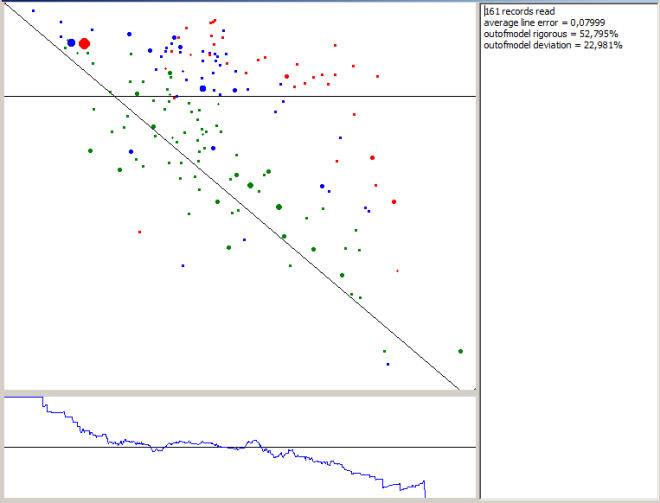
Points on graph: real results of 161 battles. Green - good concordance of model results with real results, blue - average, and red - bad concordance.
Vertical axis is battle result (horizontal black line is "0": above - victory, below - defeat), horizontal axis - battle results calculated by Monte-Carlo. Oblique black line is 1:1.
Lower graph is empiric victory chance, black line - 50%.
The Monte-Carlo algorithm input is:
N and HP of enemy
N and HP of player
A few generalized map properties (area, %free area, average tiles visible from a map tile)
The method models the following:
a local battle of player against a few bots.
Chance of player ammo shortage & ammo collection
Chance of another enemy bots enter the local battle
What IS NOT modeled:
Successful hiding.
Successful use of bottlenecks.
Bazookas.
Based on ~10000 model battles I get
botstogether - how many bots attack the player together
bestscore,worstscore - best and worst score
averagegoodscore,averagebadscore - average good and bad scores
averagescore - average score
scoredeviation - average dispersion
outofammochance - Chance that at least once the player will feel ammo shortage.
victorychance - victory chance
battleturns - a very good lower estimate of battle length
Well... 53% empiric results are outside averagegoodscore...averagebadscore
E.g. the "last to the right victory" ended up in score 21%, while calculations give Average score: -238,73% Best score: 27,5% Average good score: -174,71% Average bad score: -262,82% Worst score: -313% Victory chance: 0,04%
Hard to say what to do

There is a possibility to model a real battle, based on real bots characteristics and locations, real properties of their weapons. However, that result might be also inadequate. Moreover, such modeling will take much more computational time (and I have no statistics to backward-calculate a decent amount of empiric data).